
Most teams today are not struggling to detect incidents. They are struggling to resolve them fast enough.
Alerts fire quickly. Monitoring tools are sophisticated. Dashboards are full of data. Yet incidents still take longer than expected to resolve. The delay usually begins after detection, when teams try to understand what actually broke, who owns it, and what action should be taken.
This is where MTTR expands.
In 2026, reducing Mean Time to Resolution is no longer about adding more monitoring. It is about removing friction from diagnosis, decision-making, coordination, and execution. The organizations that succeed are the ones that treat incident response as a system, not a series of manual steps.
What MTTR Actually Includes
MTTR is often treated as a single metric, but in practice it is a combination of multiple stages.
A typical incident lifecycle includes:
- Acknowledge
- Escalate
- Investigate
- Identify
- Monitor
- Resolve
Each stage introduces potential delays. Improving MTTR requires improving each of these stages individually rather than focusing only on the final fix.
For example, an issue may be detected instantly but still take hours to resolve if teams spend excessive time identifying the root cause or coordinating ownership.
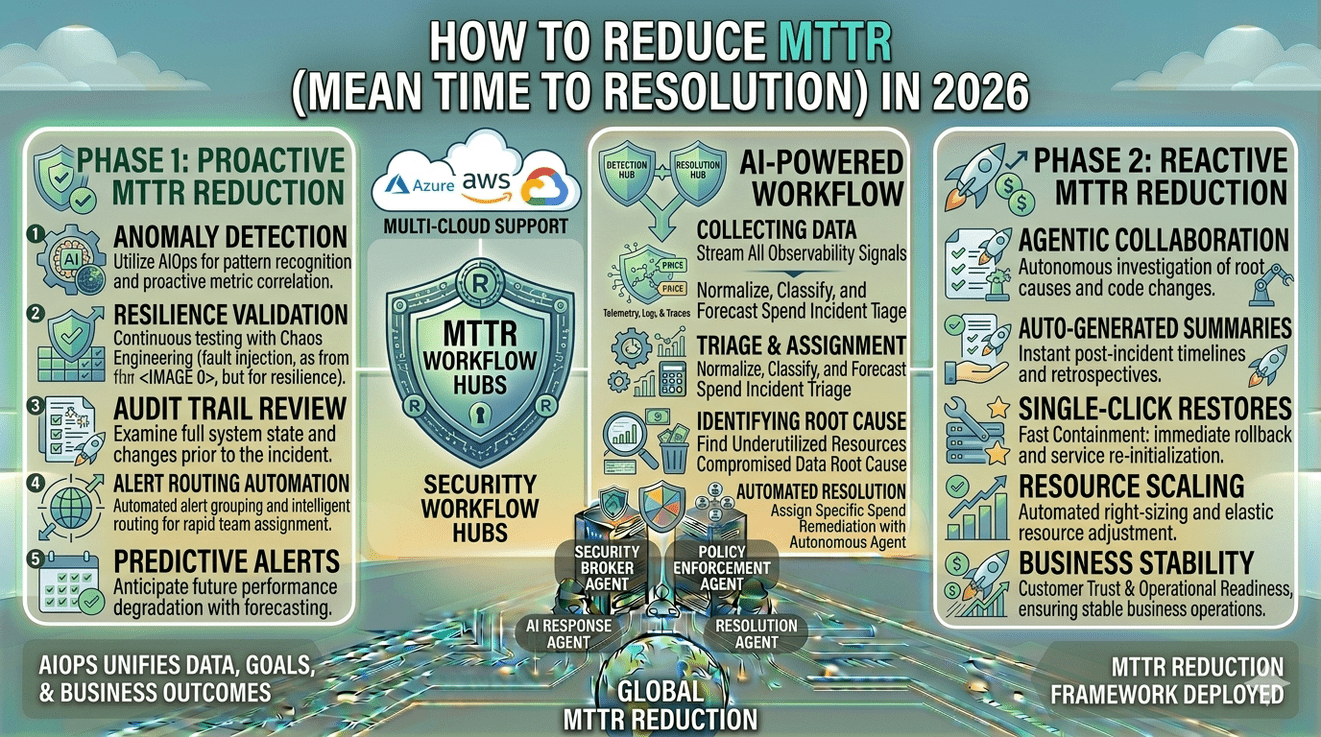
Breaking MTTR into MTBF, MTTA, and MTTR
A more useful way to approach MTTR is to break it into measurable components.
- MTBF (Mean Time Between Failure): How long a repairable system operates before breaking down
- MTTA (Mean Time to Acknowledge): How quickly teams respond and take ownership
- MTTR (Mean Time to Resolve): How long it takes to fix the issue completely
Many organizations focus heavily on detection, but delays often occur in acknowledgement and resolution.
For example:
- Alerts may trigger instantly, but ownership is unclear
- Teams may acknowledge the issue, but lack context to act quickly
- Resolution may be delayed due to dependency mapping or escalation gaps
Reducing MTTR effectively means optimizing all three.
Where MTTR Actually Breaks Down in Real Systems
In practice, MTTR rarely increases because engineers are slow. It increases because systems and workflows introduce friction.
Common breakdown points include:
- Alerts that lack context, forcing manual investigation
- Unclear ownership across services or teams
- Time spent identifying dependencies and impact scope
- Duplicate investigations across teams
- Delayed escalation due to uncertainty
- Context switching between multiple tools
- Waiting for approvals or confirmations
These delays compound quickly. Even small inefficiencies across stages can turn a short incident into a prolonged one.
Understanding where time is lost is the first step toward reducing it.
Using AI-Driven Observability to Accelerate Detection and Diagnosis
AI-driven observability plays a central role in reducing MTTR by improving both detection and investigation.
Traditional monitoring systems rely on static thresholds. Modern systems analyze patterns across metrics, logs, and traces in real time. This allows them to:
- Detect anomalies earlier
- Correlate related alerts
- Identify likely root causes
- Reduce noise from irrelevant signals
Instead of presenting dozens of alerts, AI systems surface fewer, more meaningful signals with context.
This significantly reduces the time engineers spend figuring out what is actually wrong.
Automating Root Cause Analysis to Reduce Investigation Time
Root cause analysis is often the most time-consuming phase of an incident.
In distributed systems, symptoms appear across multiple services. Engineers may spend significant time tracing dependencies before identifying the actual failure point.
AI-assisted systems help by:
- Mapping service dependencies automatically
- Highlighting correlated failures
- Identifying recent changes or deployments
- Suggesting likely causes based on historical patterns
This does not eliminate the need for human validation, but it narrows the problem space quickly and reduces investigation time.
Runbooks as a System, Not Just Documentation
Runbooks are often treated as static documents. In mature systems, they function as operational systems.
A strong runbook framework includes:
- Standardized response workflows
- Predefined decision paths
- Automated execution for known scenarios
- Clear ownership and escalation rules
When integrated into incident workflows, runbooks can:
- Trigger automated remediation actions
- Reduce decision-making delays
- Ensure consistent responses across teams
For example:
- Restarting failed services automatically
- Rolling back problematic deployments
- Scaling infrastructure in response to load
- Re-routing traffic during outages
Automated runbooks reduce both cognitive load and execution time, which directly improves MTTR.
Reducing Alert Fatigue with Actionable Alerts
One of the biggest contributors to high MTTR is alert fatigue.
When teams receive too many alerts:
- Important signals are missed
- Response slows down
- Engineers become desensitized
Reducing MTTR requires improving alert quality.
Effective alerting systems:
- Prioritize high-impact incidents
- Provide context within the alert itself
- Map alerts to service ownership
- Eliminate duplicate or redundant signals
An alert should not just indicate that something is wrong. It should help teams understand what is wrong and what needs to happen next.
Improving Incident Coordination Across Teams
Modern incidents rarely involve a single system or team.
They often require coordination across:
- Engineering
- DevOps
- Security
- Support
- Product
Without structured coordination, delays increase as teams work in silos or duplicate effort.
Incident management platforms help by:
- Centralizing updates and timelines
- Assigning clear ownership
- Tracking actions in real time
- Reducing communication gaps
Platforms such as Incipulse support synchronized communication across Slack, Teams, email, SMS, and status pages, ensuring that all stakeholders remain aligned during resolution.
Faster coordination leads directly to faster resolution.
Why Communication Directly Impacts MTTR
Communication is often treated as a separate layer, but it directly affects resolution speed.
When communication is unclear:
- Teams wait for confirmation
- Escalation slows down
- Decisions are delayed
- Support noise increases
Clear communication ensures that:
- Teams understand the situation quickly
- Actions remain aligned
- Stakeholders do not create additional pressure
This allows engineers to focus on resolving the issue instead of managing confusion.
Shift-Left Reliability: Reducing MTTR Before Incidents Happen
One of the most important shifts in 2026 is reducing MTTR before incidents even occur.
This involves improving systems earlier in the lifecycle through:
- Better testing and validation
- Pre-production observability
- Release monitoring
- Failure simulation and chaos engineering
By identifying weaknesses before they reach production, organizations reduce both the frequency and duration of incidents.
MTTR improves not only because incidents are resolved faster, but because fewer complex incidents occur in the first place.
Before vs After: What MTTR Improvement Looks Like
| Without Structured MTTR Strategy | With AI and Automation |
| Alerts lack context and require manual investigation | Alerts include context and probable root cause |
| Teams take time to identify ownership | Ownership is mapped automatically |
| Engineers manually trace dependencies | Systems highlight impacted services instantly |
| Response actions are decided manually | Runbooks trigger predefined actions |
| Communication is fragmented across tools | Updates are centralized and synchronized |
| Resolution depends heavily on individual expertise | Resolution follows structured, repeatable workflows |
The difference is not just speed. It is consistency and predictability under pressure.
Conclusion
Reducing MTTR in 2026 is not about working faster. It is about removing friction from the entire incident lifecycle.
AI-driven observability improves detection and diagnosis. Automated runbooks reduce execution delays. Better alerting reduces noise. Structured coordination improves team efficiency. Shift-left practices reduce incident complexity before it reaches production.
Organizations that succeed are the ones that treat incident response as a system. They focus on eliminating delays across every stage rather than optimizing isolated parts.
MTTR improves when systems, processes, and teams work together to reduce time lost between detection and action.
FAQs
What is MTTR in modern incident management?
MTTR, or Mean Time to Resolution, represents the total time taken to resolve an incident from detection to full recovery. It includes multiple stages such as acknowledgement, diagnosis, escalation, and communication, not just the technical fix.
How can organizations reduce MTTR effectively?
Reducing MTTR requires a combination of AI-driven observability, automated remediation, structured runbooks, and improved incident coordination. The goal is to reduce delays at each stage of the incident lifecycle rather than focusing only on faster resolution.
Why does MTTR remain high even with modern monitoring tools?
Monitoring tools improve detection, but MTTR often increases due to delays in diagnosis, ownership identification, and coordination across teams. These operational gaps slow down response even when issues are detected quickly.
What role does automation play in MTTR reduction?
Automation reduces manual effort during incidents by triggering predefined actions, executing runbooks, and eliminating repetitive tasks. This allows teams to focus on higher-level decision-making and speeds up resolution.
