
Most SaaS companies start thinking seriously about reliability only after something goes wrong.
Maybe customers complain about repeated outages. Maybe enterprise prospects start asking difficult uptime questions during procurement calls. Maybe internal teams realize they are tracking dozens of metrics without knowing which ones actually matter.
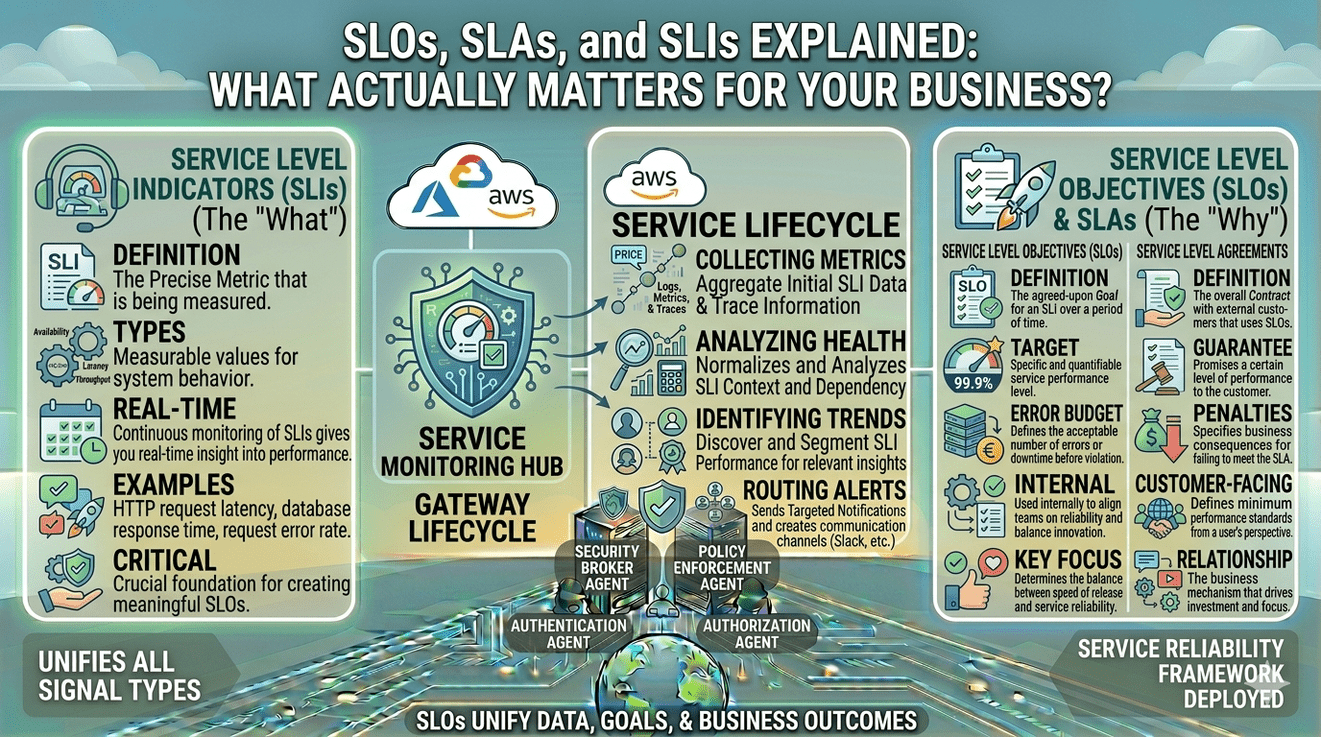
That is usually when terms like SLI, SLO, and SLA start appearing in conversations.
The problem is that these terms are often treated as interchangeable, even though they represent completely different things. Teams end up measuring the wrong indicators, setting unrealistic reliability targets, or making contractual promises that engineering cannot realistically support.
At a surface level, the definitions seem simple:
- SLI measures performance
- SLO defines the target
- SLA formalizes the promise
But in practice, the relationship between them affects far more than uptime reporting. It shapes incident response priorities, engineering investment, customer trust, support expectations, and even revenue risk.
Understanding what each one actually means is important. Understanding which one matters most for the business is even more important.
Understanding How SLIs, SLOs, and SLAs Work Together
The easiest way to think about these concepts is as a progression from measurement to commitment.
An SLI measures what is happening.
An SLO defines what the team aims to achieve.
An SLA establishes what has been promised externally.
For example:
- SLI: “API uptime was 99.95% last month.”
- SLO: “Our target uptime is 99.9%.”
- SLA: “If uptime falls below 99.9%, customers receive service credits.”
Each layer depends on the previous one. Without reliable measurement, targets become meaningless. Without realistic targets, contractual guarantees become risky.
This is why mature SaaS teams treat SLIs, SLOs, and SLAs as connected operational systems rather than isolated reliability terms.
What Is an SLI (Service Level Indicator)?
A Service Level Indicator is the actual measurement of service performance.
It tells you how the system is behaving in measurable terms. Common examples include:
- Uptime percentage
- API response time
- Error rate
- Request success rate
- Latency
- Availability by region
For example, a SaaS platform may track:
- 99.97% uptime
- 220ms average API latency
- 0.05% failed requests
These are indicators because they describe observed performance, not goals or commitments.
Why SLIs Matter More Than Most Teams Think
One of the biggest mistakes SaaS companies make is assuming that more monitoring automatically means better reliability.
In reality, teams often collect large volumes of operational data without identifying which indicators actually reflect customer experience. This creates noisy dashboards rather than meaningful operational insight.
A useful SLI should measure something customers genuinely notice.
For example:
- A fintech platform may prioritize payment success rates.
- A video platform may focus on buffering latency.
- An e-commerce company may care more about checkout reliability than homepage response times.
The strongest SLIs connect infrastructure performance to real customer impact.
That distinction matters because internal system health and customer experience are not always aligned. A database may appear healthy from an infrastructure perspective while customers experience failed transactions or degraded workflows.
If the SLI does not reflect user experience, reliability reporting becomes misleading.
Common Problems Teams Face with SLIs
Another common issue is over-measurement.
Not every metric deserves operational attention. When teams track too many low-value indicators, prioritization weakens. Engineers spend time reacting to noise instead of focusing on genuinely customer-impacting degradation.
This often leads to alert fatigue, inconsistent escalation, and confusion during incidents.
Strong SLIs are selective. They prioritize signals that represent meaningful business impact rather than technical activity alone.
What Is an SLO (Service Level Objective)?
A Service Level Objective defines the target reliability level the organization aims to maintain.
If the SLI measures reality, the SLO defines acceptable performance expectations.
Examples include:
- Maintain 99.9% monthly uptime.
- Keep API latency below 300ms for 95% of requests.
- Resolve critical incidents within 30 minutes.
Unlike SLAs, SLOs are usually internal operational targets rather than contractual guarantees.
They help engineering teams make decisions about reliability priorities, deployment risk, and operational trade-offs.
Why SLOs Matter Beyond Uptime Reporting
A lot of companies treat SLOs as reporting metrics. Mature teams use them as decision-making tools.
SLOs help organizations answer questions such as:
- Are reliability standards improving or degrading?
- Is deployment velocity introducing too much operational risk?
- Is technical debt affecting service stability?
- Are infrastructure investments justified?
Without clearly defined objectives, teams often swing between overengineering and reactive firefighting.
SLOs create operational boundaries. They define what level of unreliability is acceptable and when intervention becomes necessary.
The Business Side of Reliability Targets
One of the most overlooked aspects of SLO design is cost.
Aggressive uptime targets sound impressive externally, but they are expensive operationally. Achieving extremely high availability often requires:
- Multi-region redundancy
- Advanced failover systems
- Extensive monitoring infrastructure
- Larger operational teams
- Higher cloud costs
For some businesses, that investment makes sense. For others, it creates diminishing returns.
A SaaS product used occasionally by small teams may not require the same reliability investment as a financial platform processing real-time transactions.
Good SLOs balance:
- Customer expectations
- Operational capability
- Engineering cost
- Business value
That balance is what makes SLOs strategically important rather than purely technical.
Why Error Budgets Matter in SLO Discussions
SLO conversations are incomplete without discussing error budgets.
An error budget represents the acceptable amount of unreliability allowed within a target window.
For example:
- A 99.9% uptime target allows roughly 43 minutes of downtime per month.
This changes how teams approach reliability. Instead of aiming for unrealistic perfection, teams operate within defined risk tolerance.
If the error budget is consumed too quickly, organizations may:
- Pause risky deployments
- Prioritize reliability improvements
- Slow feature releases
- Reassess infrastructure stability
Error budgets create discipline without demanding zero failure, which is rarely realistic in distributed systems.
How SLO Clarity Improves Incident Management
During incidents, SLOs help determine urgency and escalation priority.
If a service degradation threatens a critical reliability objective, escalation becomes immediate. If the issue remains within acceptable tolerance, teams can avoid unnecessary operational panic.
This is where reliability metrics connect directly to incident management maturity.
Platforms such as Incipulse support visibility and structured communication during outages, but communication becomes significantly more effective when teams already understand which objectives and customer-facing experiences are actually at risk.
Without clear SLOs, incident prioritization becomes inconsistent and reactive.
What Is an SLA (Service Level Agreement)?
A Service Level Agreement is the formal commitment a company makes to customers regarding service reliability and performance.
Unlike SLIs and SLOs, an SLA is not just an operational guideline. It is a business agreement that defines:
- What level of service customers should expect
- How service performance will be measured
- What happens if those commitments are not met
A typical SaaS SLA may include:
- Guaranteed uptime percentage
- Response or resolution timelines
- Support availability
- Service credit policies
- Exclusions for planned maintenance
For example:
“The platform will maintain 99.9% monthly uptime. If uptime falls below this threshold, eligible customers will receive service credits.”
At this stage, reliability becomes more than an engineering discussion. It becomes a customer trust and financial accountability issue.
Why SLAs Matter More to Customers Than Internal Metrics
Customers rarely ask about your internal SLO framework during procurement discussions.
What they care about is:
- Whether the platform will remain reliable
- What level of downtime is considered acceptable
- How transparent the company will be during incidents
- What protections exist if reliability expectations are not met
This is why SLAs carry business weight. They convert operational reliability into customer-facing accountability.
For enterprise customers especially, SLAs influence:
- Vendor selection
- Renewal confidence
- Procurement approval
- Compliance reviews
- Risk assessment
An unreliable platform damages trust. A vague or unrealistic SLA damages credibility.
The Biggest Mistake Companies Make with SLAs
One of the most common mistakes is treating SLAs as marketing tools rather than operational commitments.
Some companies publish aggressive uptime guarantees simply because competitors do the same. Internally, however, their infrastructure, monitoring, and incident management processes may not realistically support those commitments.
This creates a dangerous gap between:
- What engineering can sustain
- What sales promises externally
Eventually, that gap surfaces during incidents.
If repeated SLA breaches occur, customers stop trusting not only the agreement but the organization itself.
Strong SLAs are grounded in operational reality, not aspirational branding.
Why SLAs Without Strong SLOs Become Risky
An SLA should never exist independently from SLOs.
If your organization promises 99.9% uptime contractually but internally operates without clearly defined reliability objectives, the SLA becomes difficult to defend operationally.
This is why mature reliability programs usually work in this order:
- Define meaningful SLIs
- Establish realistic SLOs
- Build SLAs around achievable objectives
The SLO acts as the operational safety buffer behind the SLA.
For example:
- Internal SLO: 99.95%
- External SLA: 99.9%
This gap provides breathing room. It allows engineering teams to absorb operational variability without immediately triggering contractual penalties.
Without that buffer, every reliability fluctuation becomes a business risk.
Why Overpromising Reliability Creates Long-Term Problems
Many growing SaaS companies underestimate the operational cost of extreme reliability guarantees.
A 99.9% uptime commitment already allows very little downtime. A 99.99% or 99.999% target increases operational complexity dramatically.
Achieving higher availability often requires:
- Multi-region failover
- Advanced redundancy architecture
- Continuous monitoring
- Faster incident response
- Larger infrastructure budgets
- More operational staffing
The difference between “three nines” and “five nines” is not incremental. It is exponential in terms of complexity and cost.
This is why reliability targets must align with actual business requirements rather than perception alone.
Not every SaaS platform needs ultra-high availability guarantees. What matters is whether reliability expectations match customer dependency and usage patterns.
How SLAs Affect Incident Management
SLAs heavily influence incident response urgency.
Once contractual commitments are involved, outages are no longer just technical issues. They become business liabilities.
For example:
- A minor degradation affecting internal tooling may not require executive escalation.
- A customer-facing outage threatening SLA thresholds may immediately trigger high-priority incident response.
SLAs also affect communication expectations. Customers operating under formal agreements expect:
- Faster acknowledgement
- Clear updates
- Defined timelines
- Transparent reporting
This is where structured communication becomes operationally critical.
Platforms such as Incipulse help teams centralize updates across status pages, Slack, Teams, email, and SMS so communication remains consistent during SLA-sensitive incidents.
When contractual trust is involved, communication discipline matters as much as technical recovery.
SLOs vs SLAs: What Actually Matters More?
This is where many businesses get confused.
SLAs receive more external attention because customers see them directly. However, SLOs are usually more important operationally.
Why?
Because strong SLOs are what make reliable SLAs possible.
An SLA is ultimately an outcome of operational maturity. If internal objectives are poorly designed, unrealistic, or inconsistently measured, external guarantees eventually fail.
You can think of it this way:
- SLIs tell you what is happening.
- SLOs help you manage reliability proactively.
- SLAs define the consequences when reliability commitments are not met.
From a business perspective, SLOs often drive long-term success more than SLAs because they influence engineering behavior before customer trust is damaged.
Which One Should SaaS Companies Prioritize First?
For growing SaaS teams, the smartest approach is usually:
- Define customer-relevant SLIs
- Build realistic SLOs around them
- Introduce SLAs only when operational maturity supports them
Jumping directly to aggressive SLAs without reliable measurement and objective tracking creates unnecessary risk.
The strongest reliability programs evolve gradually. They align technical capability with customer expectation rather than treating reliability purely as a sales differentiator.
A Simple Way to Think About All Three
A useful way to frame these concepts internally is:
| Concept | Purpose | Audience |
| SLI | Measures actual performance | Engineering teams |
| SLO | Defines reliability targets | Internal operations |
| SLA | Establishes customer commitments | Customers and legal teams |
Together, they create a structured reliability system.
Separately, they create confusion.
Conclusion
SLIs, SLOs, and SLAs are not interchangeable reliability buzzwords. They represent different layers of operational maturity.
SLIs measure service performance. SLOs define acceptable reliability goals. SLAs formalize customer-facing commitments and consequences.
For most SaaS businesses, the real value lies not in publishing aggressive uptime guarantees but in building a reliability framework grounded in realistic measurement and operational discipline.
Customers do not expect perfection. They expect consistency, transparency, and accountability when issues occur.
The companies that manage reliability well are not necessarily the ones with the fewest incidents. They are the ones that understand exactly what they are measuring, what they are promising, and what level of reliability the business can realistically sustain.
FAQs
What is the difference between an SLI, SLO, and SLA?
An SLI measures actual service performance, an SLO defines the internal reliability target, and an SLA formalizes the customer-facing commitment with consequences if targets are not met.
Why are SLOs important for SaaS companies?
SLOs help teams define acceptable reliability standards, prioritize operational improvements, and manage engineering trade-offs before customer trust is affected.
Can a company have SLOs without SLAs?
Yes. Many organizations use SLOs internally before introducing formal SLAs. This allows teams to mature operationally before making contractual guarantees.
Why do unrealistic SLAs create problems?
Aggressive SLAs increase operational pressure and financial risk if infrastructure and incident response processes cannot consistently support them.
What role do error budgets play in reliability management?
Error budgets define the acceptable amount of unreliability allowed within an SLO target. They help teams balance stability with deployment speed and innovation.
